What's the Big Deal with Vector Databases?
Storyblok is the first headless CMS that works for developers & marketers alike.
The recent explosion in AI capabilities has not been driven just by LLMs. From chatbots that can accurately answer questions from a knowledge base, to powering search bars that understand user intent, developers are now tasked with creating applications that perform truly content-aware operations. These features require a system that goes beyond simple keyword matching and grasps the semantic meaning of the data it manages. The engine powering this new class of applications is the vector database.
This article is the first in a three-part series that aims to demystify vector databases.
1. The “What & Why” (you are here): a conceptual introduction to what a vector database is, why it's a game-changer, and what its core use cases are.
2. The “How”: a practical, hands-on tutorial where we build a project that demonstrates the technology in action.
3. The “Real World”: an advanced guide covering production factors, including scaling, hybrid search, and architectures like Retrieval-Augmented Generation (RAG).
At Storyblok, we develop solutions that enable our CMS to do more than manage stories and assets, ensuring your content is smarter and AI-ready.
This vision has led to our latest offering, Strata (opens in a new window). A custom vector database that’s based on your content and redefines what you can do with it.
In this series, we share the foundational knowledge behind Strata, starting with the core concept.
Beyond keyword search: from lexical to semantic
For years, the gold standard for full-text search has been lexical search algorithms, such as Okapi BM25 (opens in a new window). Used by search engines like Elasticsearch (opens in a new window) and Lucene, BM25 (or best matching) is a sophisticated ranking function that scores documents based on term frequency (TF) and inverse document frequency (IDF). In essence, it finds and ranks documents by matching the specific keywords in a query, giving more weight to terms that occur more frequently in a document and to less commonly used terms (also known as stop words (opens in a new window)). It is highly effective and a massive improvement over simple pattern matching.
However, its limitation is that it is fundamentally lexical, not semantic. It doesn’t understand the meaning or intent behind the words. A BM25-powered search for “vehicles that travel on water” will excel at finding documents containing the exact words “vehicles”, “travel”, and “water”. It will, however, completely disregard an article about “my new yacht” or a page comparing “different kinds of ships and canoes”. In other words, lexical search understands the words you type, not the concept you’re interested in. This semantic gap is precisely the problem that vector databases are designed to solve.
Turning content into coordinates: vector embeddings
Vector databases operate on the data’s semantic meaning by first converting input (text, images, and anything we typically call “content”) into a numerical form called a vector embedding. This process uses a specialized neural network, known as an embedding model, to transform unstructured content into an n-dimensional vector of floating-point numbers. Specialized models can transform text tokens (words, phrases) into embeddings, and the same extends to other unstructured data: images, audio, and video can be embedded using modality-specific models, to capture their semantics.
[[0.123, 0.456, 0.789, …], [0.987, 0.654, 0.321, …], …]
These vectors are not arbitrary. They are rich mathematical representations of the content’s meaning, that encode the semantic relationships of the source data to create geometric correlations in the vector space. Think of these vectors as coordinates on a vast, multidimensional “meaning map”. On this map, an article about “affordable snowy vacations” and a blog post about “cheap winter getaways” will be plotted as near neighbors. This process effectively distills the core concepts of the content into a dense numerical format that a machine can understand and compare.
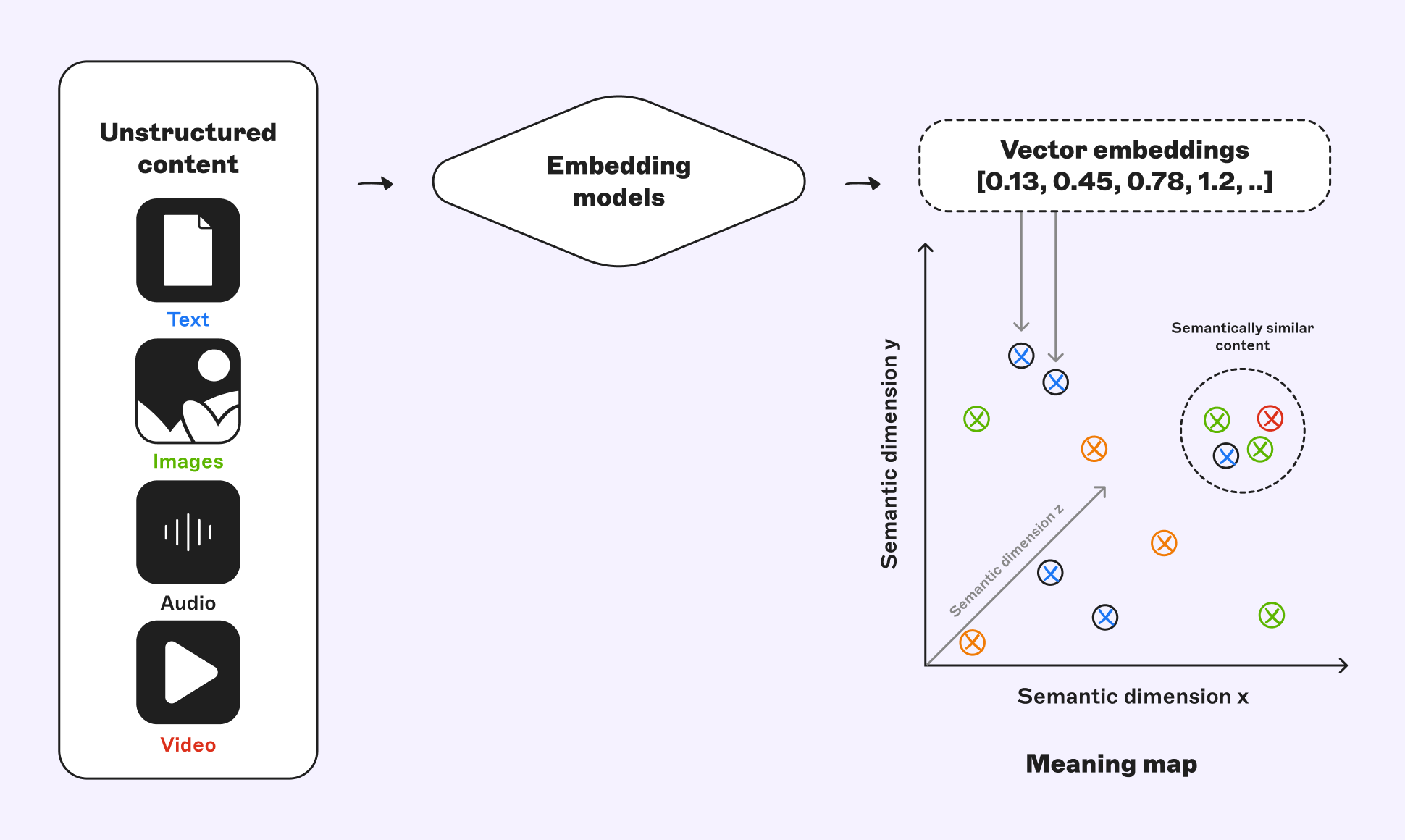
Semantic retrieval: how vector search works
Once content is converted into vectors, the retrieval process is fundamentally different. When a user submits a query, it’s passed through the same embedding model to create a query vector. Then, the database performs a similarity search to find the stored vectors that are “closest” to the query vector in that n-dimensional space.
This proximity is calculated using a distance metric, and if you are interested in the very technical details I suggest you to read this post (opens in a new window) by Chris Emmery, but in short the two most common metrics are:
Cosine similarity
Measures the angle between two vectors. It focuses on the direction (semantic meaning), and ignores vector length (magnitude). This makes cosine similarity the preferred metric for text embeddings and RAG, as it successfully captures conceptual similarity regardless of document length. Common uses include embedding-based search (OpenAI Text Embedding (opens in a new window), Sentence-BERT (opens in a new window)), RAG retrieval, semantic deduplication (for example, detecting duplicate articles or FAQs), and topic clustering of documents.
Euclidean distance (with L² norm)
Measures the straight-line distance between the two vector endpoints. It’s the default in tasks where absolute distances matter, including k (opens in a new window)-means (opens in a new window) and DBSCAN (opens in a new window) clustering, color quantization (opens in a new window) in RGB/Lab space, face recognition with systems such as FaceNet (opens in a new window), where thresholds on L² distance decide if two samples “match”.
To search efficiently across billions of vectors, vector databases use specialized indexes for approximate nearest neighbor (ANN) (opens in a new window), enabling ultra-fast retrieval with controllable accuracy trade-offs.
The details of these indexes are the topic of our next post, but the idea is simple: find the best semantic matches, not just the best literal matches.
| Keyword search | Semantic search |
|---|---|
| Relies on exact text matches | Infers intent |
| SELECT * FROM articles WHERE content LIKE '%boat%'; | results = strata_client.search("vehicles that travel on water") |
| It’s literal. It finds “boat” but misses “yacht”, “ship”, or “canoe.” | It’s smart. It finds what you mean, not just what you type. |
So, what’s this good for?
This shift from lexical to semantic search unlocks powerful capabilities:
- Intelligent search: build a search bar that truly understands your users, returning relevant content even if the keywords don’t match exactly.
- Smarter content recommendations: suggest related articles or products based on conceptual similarity, without relying only on manual tagging.
- AI-powered Q&A: provide the retrieval mechanism for systems that answer questions using your documentation as a source of truth.
- Automated content organization: use vector similarity to automatically cluster, categorize, and identify thematic relationships in large content collections.
These are the kinds of experiences we’re building toward with Storyblok’s vector‑powered platform, Strata. Learn more on the product page.
Conclusion
Vector databases provide the means to query data based on its intrinsic meaning, not just its textual representation. By leveraging machine learning models to create rich vector embeddings, they allow us to move beyond the limitations of keyword-based search and build applications that understand concepts and intent.
We’ve covered the “what” and the “why.” In the next post in this series, we dive into the “how”, popping the hood to explore the architecture and build our first vector-powered application. Check it out here.