Setting Up the Blog Content Structure in Storyblok
Storyblok is the first headless CMS that works for developers & marketers alike.
This article is written in cooperation with VueDose. To start reading from the beginning check out the first article or use TOC at the bottom to jump to any other article.
In the previous part of this guide you implemented an ArticleCard UI component to show the data of articles. But that data was hard-coded on the page.
In this article, you will learn how to use Storyblok to create the blog content data structure that you will need to build NarutoDose, a simpler version of VueDose.
What, exactly, is the blog data structure we need to build? Let's make it simple:
- Article: it must have a title, description, publication date and the article content. An article must be written by an author.
- Author: name, bio and avatar image.
- Topics: an article might belong to different topics
With it, we cover the basics of a blog data structure: content, relationships and categorization. You can always make it more complex from there.
Additionally, Storyblok gives us free search functionality (even full-text). You'll see that later in another part of the series.
Enough talking, let's start building it!
Creating the Blog Structure
First, you need to sign up for Storyblok, assuming you haven't done it already. It's free, and possibly the only cloud-based headless CMS out there with a quite decent free plan.
Then, create a space. I'd name it NarutoDose.
If it's the first time you're using Storyblok, there is an easy to follow getting started guide so you can quickly grasp the basics.
Articles
In order to create the data of the articles, you need to create a content type which you can do while creating a folder. Go to the content tab and create an "articles" folder by clicking the folder in the top-right part of the page.
Choose "add new" content type and name it Article.
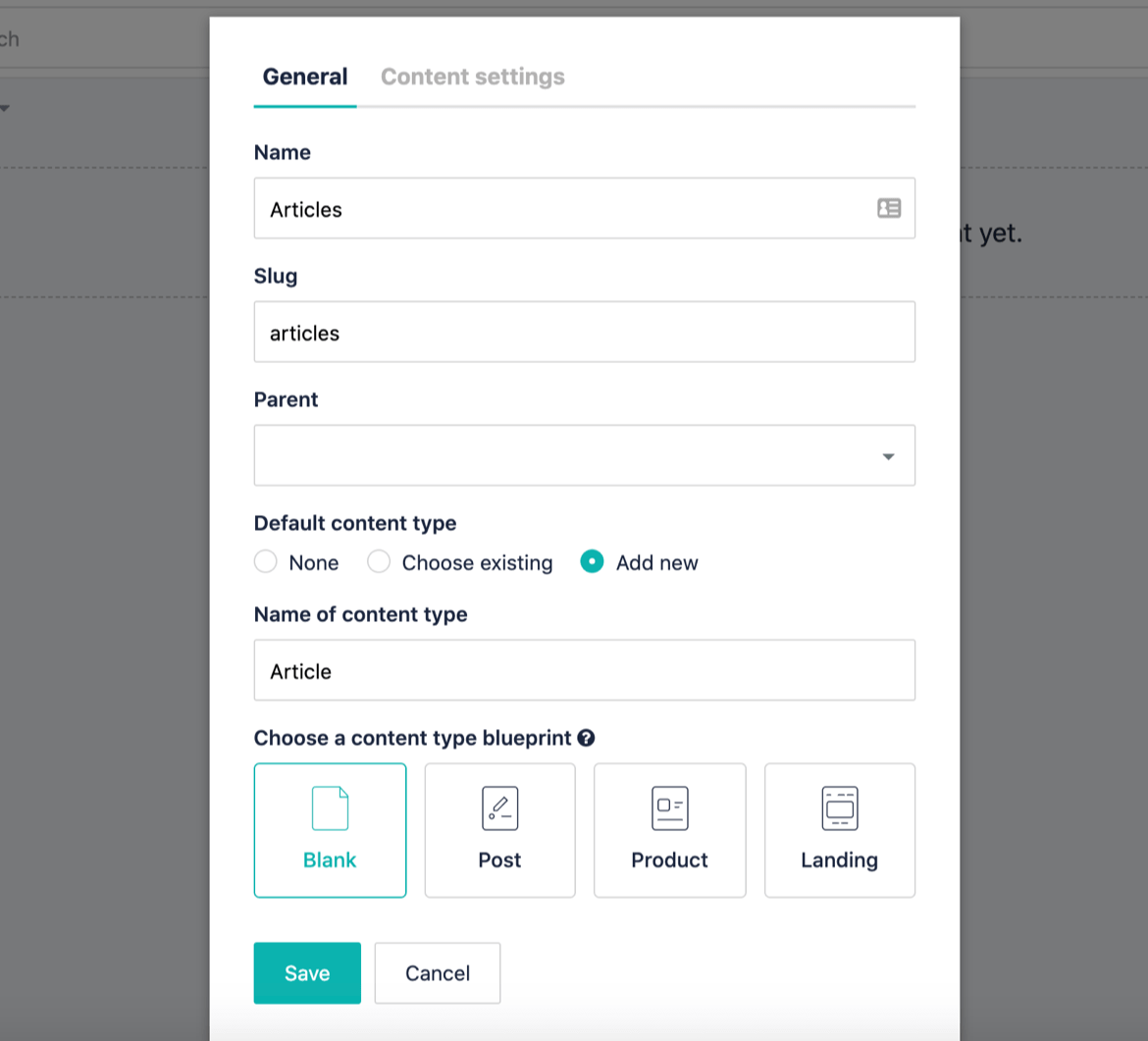
Storyblok is well known for its visual editor since it allows content creators to use components (like lists, carousels, page, separator...), coined as bloks, to build sections and pages by themselves.
These components are created on Storyblok and implemented in your favourite frontend technology.
But we're not using bloks, we're just using the content types to build schemas and work with content using the Content Delivery API.
To make this more comfortable, let's disable the visual editor and restrict the content type to only articles:
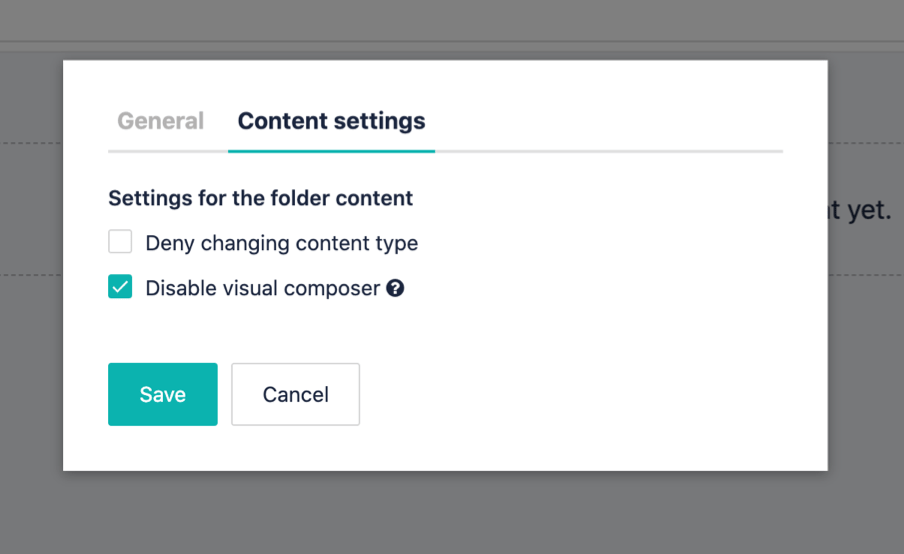
Save, and go to the Articles folder.
Now you need to define the article content type. You can do that in different ways, but maybe at this point the easiest way is to do it while creating the first article.
For that, click the "+ Entry" button and give the article a title. Once you do that, go to the article page where we can create the article content type schema by clicking the "Define schema" button:
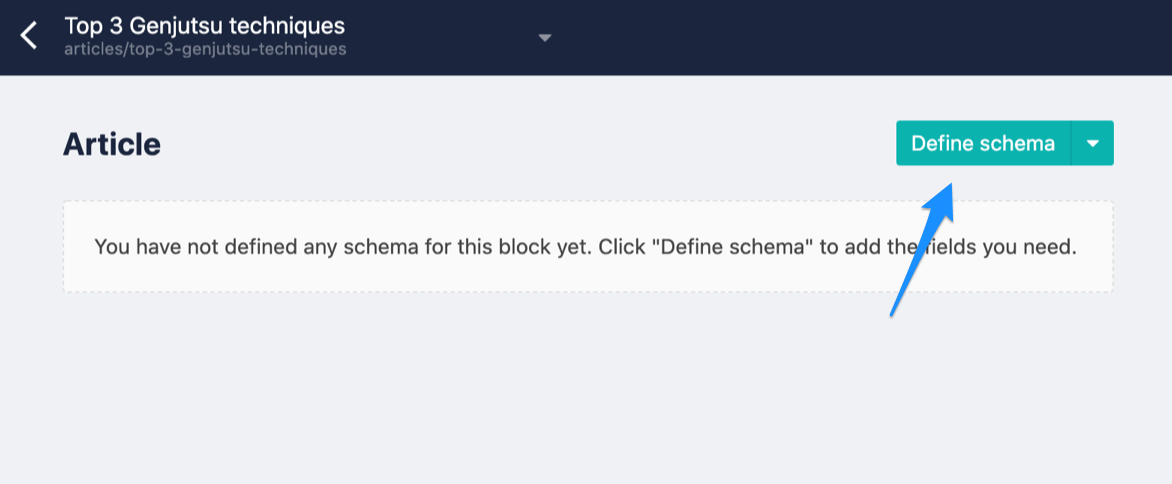
Create the schema as follows, setting title and description as text, date as datetime and content as markdown type:
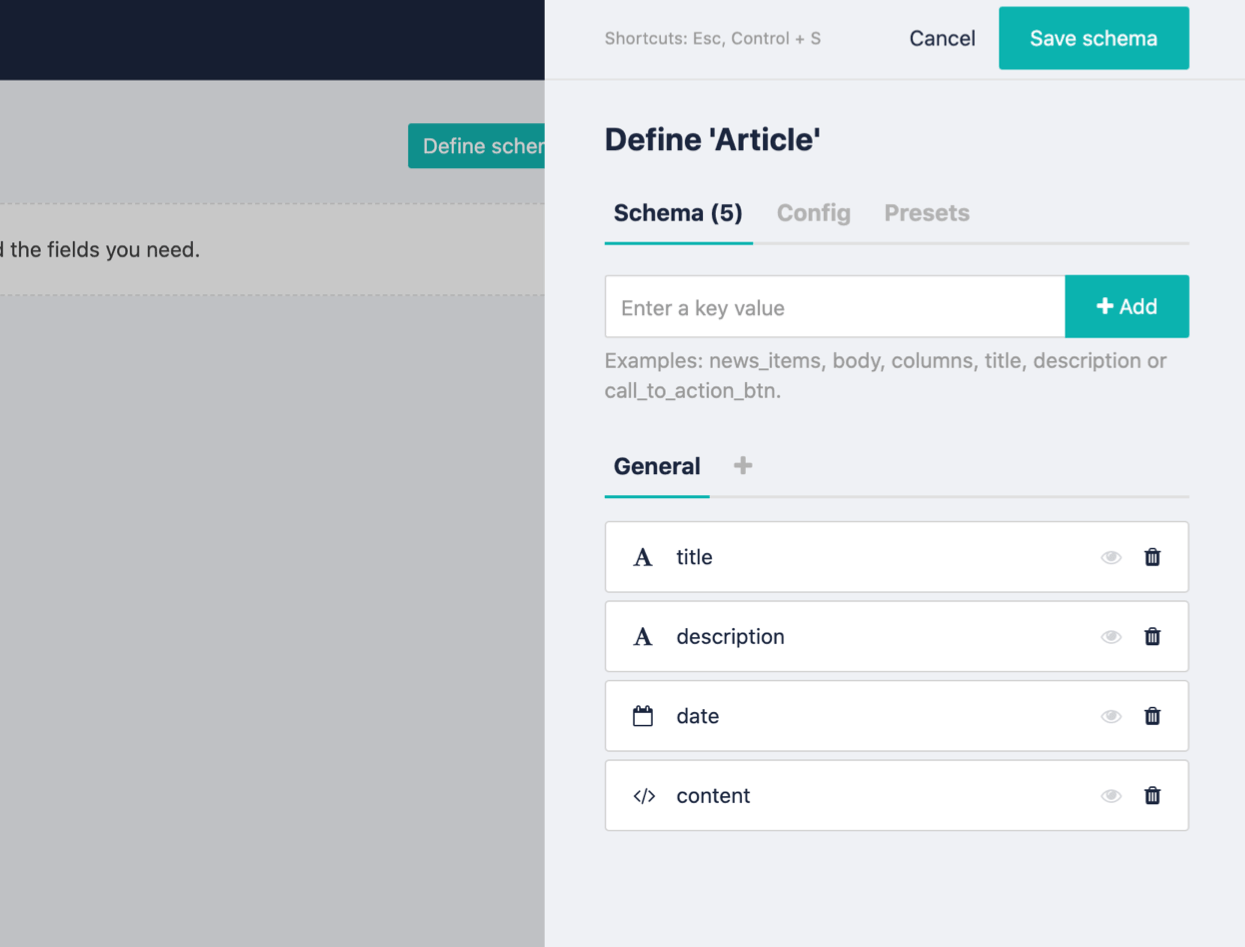
Save it and publish it.
You can now see how it looks like when we call the API- do this by clicking the Draft or Published JSON buttons, in the selections under the Publish button:
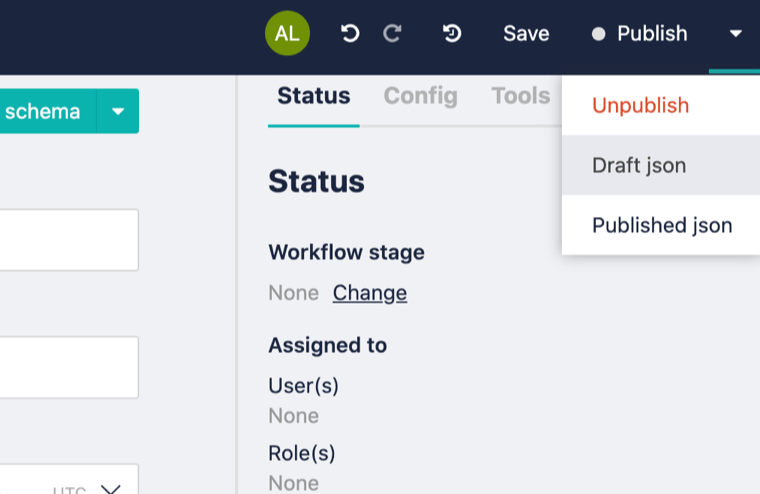
By the way, you might be confused that I've given the same title for the story name as for the article title. I was confused too.
You can see that the story name is equivalent to a file name. The title, instead, is a custom name we gave it, and in the JSON appears inside the content key:
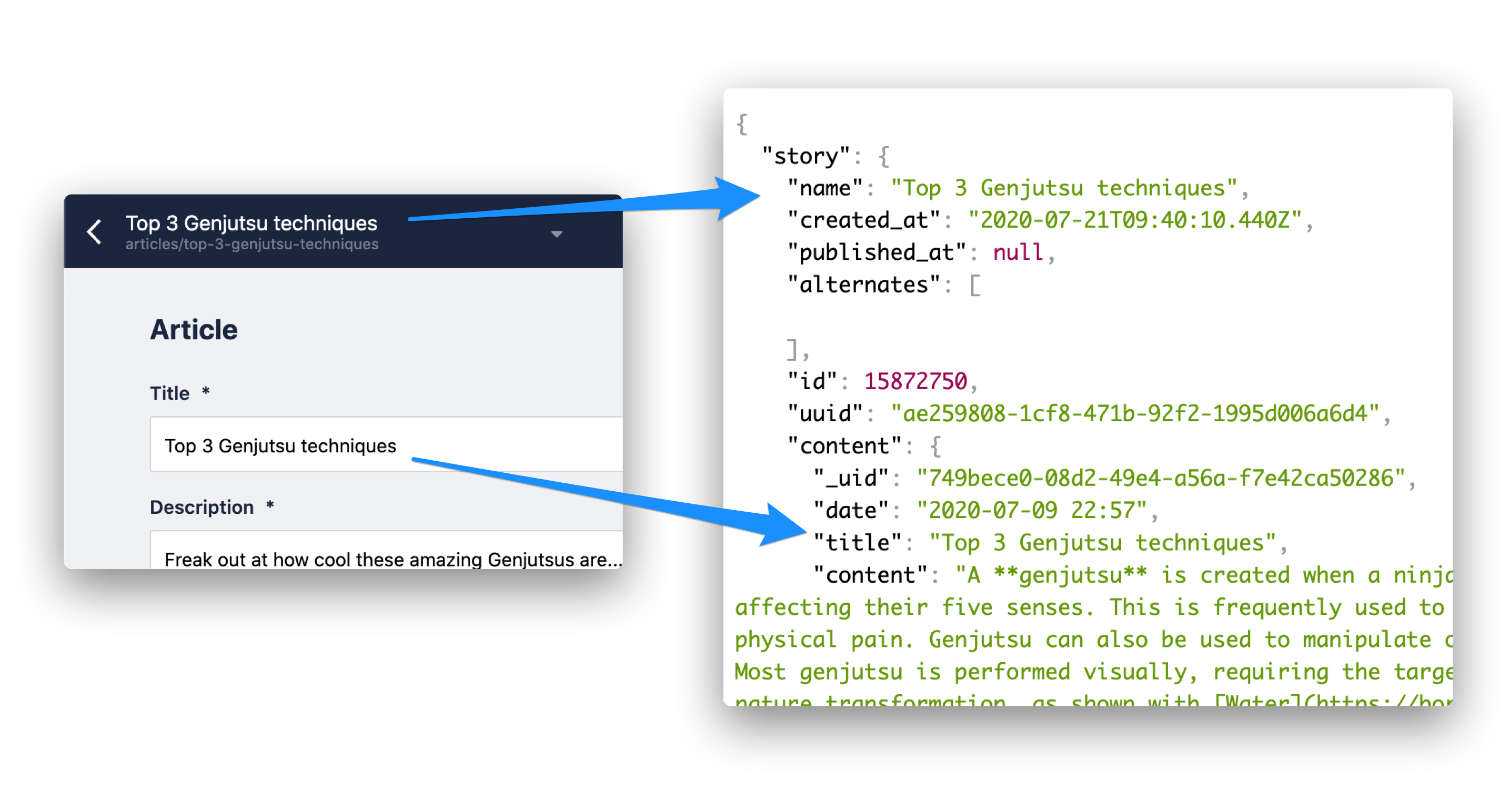
I believe is good not to use the story name for the article, product or item purposes, because it depends on the "file name". Instead, better to add a title which is not dependent on that "file system".
Authors
Following the same steps, let's create the authors. Go to the root folder and create an Authors folder. Then create the first author to set the schema as this:
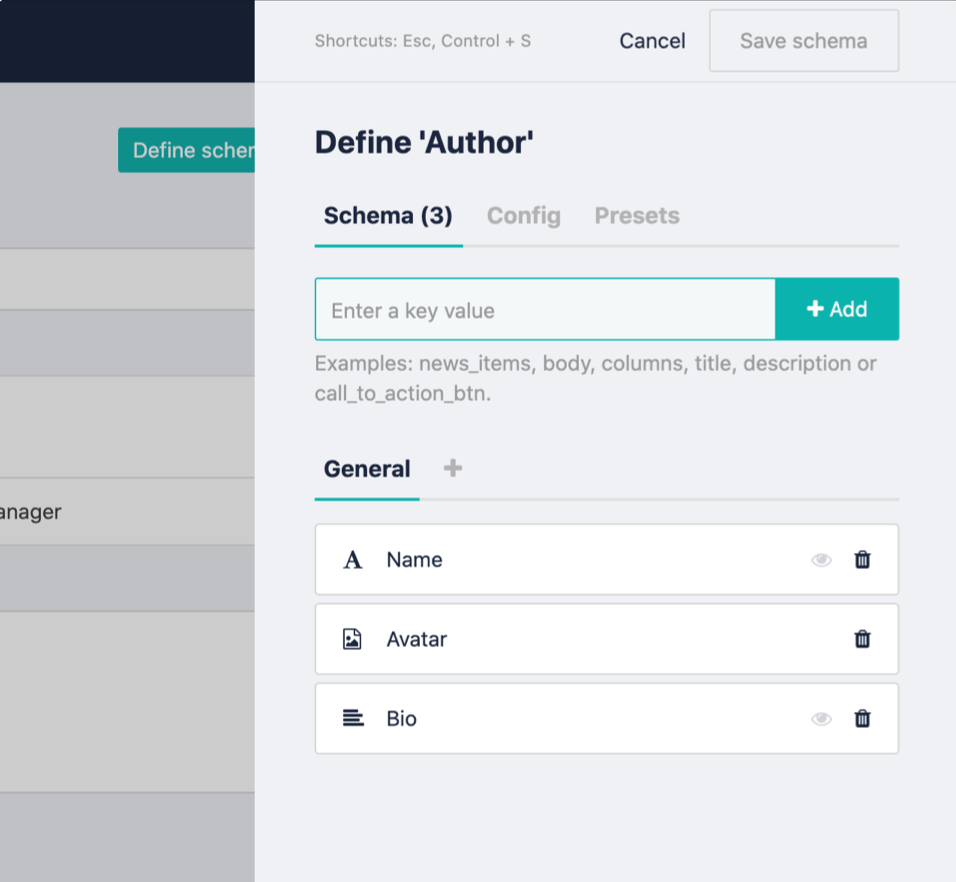
The name is a text field, avatar an asset, and bio a textarea field.
To create the first author... Well, I'm sure you know how to fill in the first author data 😉.
Authors and Articles Relationship
Once you create an author, we can create a relationship between articles and authors.
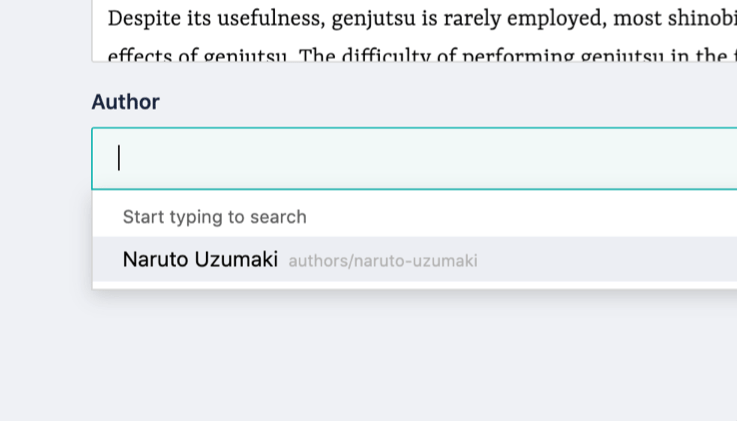
Let's go back to the article we created before and open its schema. Add an "author" field and set the type to Single Option.
Here's the important step: when you choose Single Option type, you'll see a source field. It defines the source from where the selection is going to be filled in from and is what you need to use to create the relationship.
Set it to "Stories" and write "authors/" on the Path to folder of stories in order to indicate what stories the select field will use to fill itself.
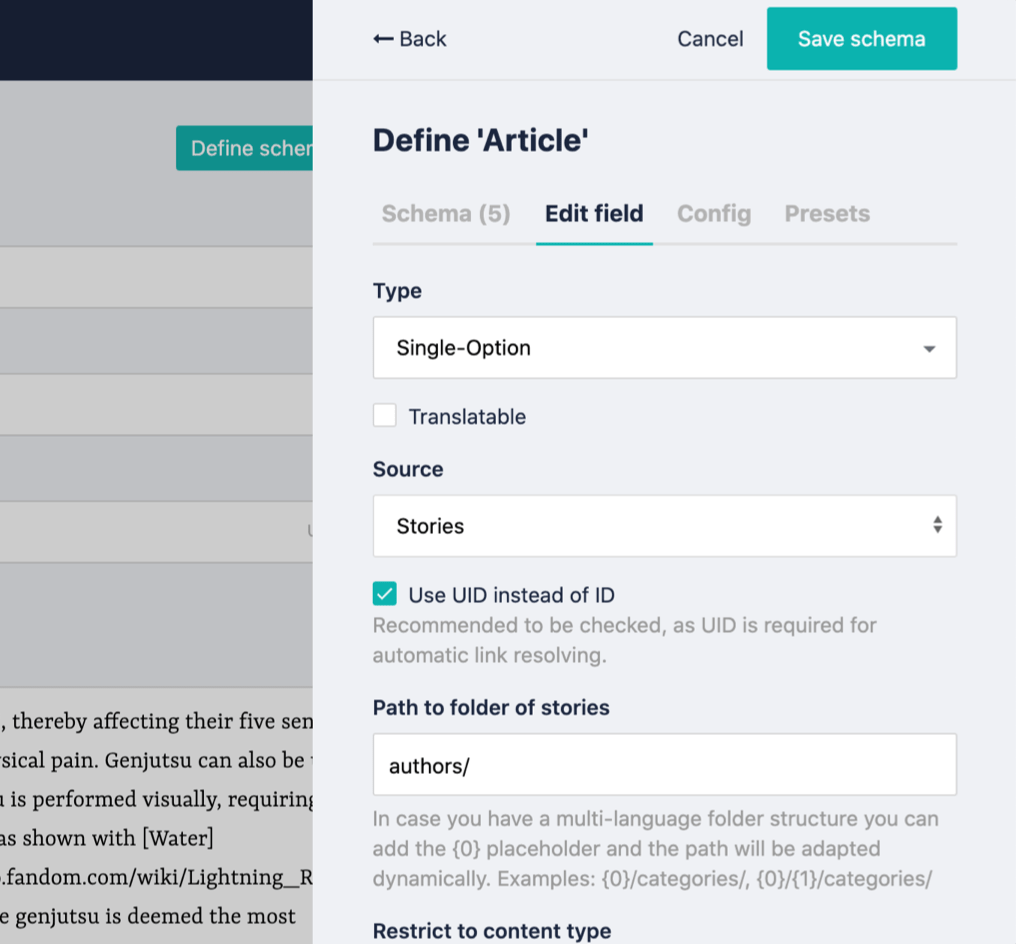
Save it and you'll see the author we created in the author options field:
Topics
To categorize the topics, you could create a content type, which is necessary if the topic has more than just a name field.
Or, to keep it simple, we can just use tags. You can set them per story and they're useful for searching and counting, as you will soon see, so we have some features for free 😉.
Additionally, a story can have multiple tags that perfectly cover our use case.
For now, just go to the article we created and add a tag or two:
Recap
At this point, you have created the basic blog structure wherein you have articles, authors and topics, including relationships and interesting features, such as search and categorization.
You learned how to create different kinds of content, as well as their schema, and choose from different fields depending on your needs.
The next step is to get our hands on the Content Delivery API to access this data and integrate it with the NarutoDose Nuxt app.
Aren't you excited? 😎
Continue reading and find out how to Show the Blog Content in Nuxt Using Storyblok API.
| Resource | Link |
|---|---|
| Part 1: Setting up a full static Nuxt site | https://vuedose.tips/setting-up-a-full-static-nuxt-site |
| Part 2: Creating UI components based on a Design System in Vue.js | https://vuedose.tips/creating-ui-components-based-on-a-design-system-in-vue-js |
| Part 4: Show the Blog Content in Nuxt Using Storyblok API | https://www.storyblok.com/tp/show-blog-content-in-nuxt |
| Part 5: Tags and Search Functionality in Nuxt Using Storyblok API | https://vuedose.tips/tags-and-search-functionality-in-nuxt-using-storyblok-api |
| Part 6: Optimize SEO and Social Media Sharing in a Nuxt blog | https://vuedose.tips/optimize-seo-and-social-media-sharing-in-a-nuxt-blog |
| Part 7: Generate and deploy the blog as a full static Nuxt site | https://vuedose.tips/generate-and-deploy-the-blog-as-a-full-static-nuxt-site |
| Getting Started Guide | https://www.storyblok.com/docs/guide/getting-started |
| Nuxt.js | https://nuxtjs.org/ |
